
ছবিটির সোর্সঃ ১ নাম্বার রেফারেন্স।
- কিভাবে করোনা ভাইরাস এর উপস্থিতি নির্নয় করা হয়?
- প্রথমেই সন্দেহজনক ব্যক্তির সোয়াব স্যাম্পল নেওয়া হয় নাকের ভেতর থেকে।
- স্যাম্পল পরীক্ষাগারে নিয়ে এসে RTPCR ( Reverse transcription polymerase chain reaction) প্রক্রিয়ার মাধ্যমে করনা ভাইরাস এর জেনেটিক কোড এর উপস্থিতি নির্নয় করা হয়।
- যদি করোনা ভাইরাস এর জেনেটিক কোড এর উপস্থিতি পাওয়া যায় তবে পজিটিভ কেইস হিসেবে রিপোর্ট করা হয়। আর পাওয়া না গেলে নেগাটিভ বা কোভিড-১৯ রোগ নাই বলে প্রকাশ করা হয়।
- পুল টেস্টিং কিভাবে করা হয়? এর উপকারিতা কি?
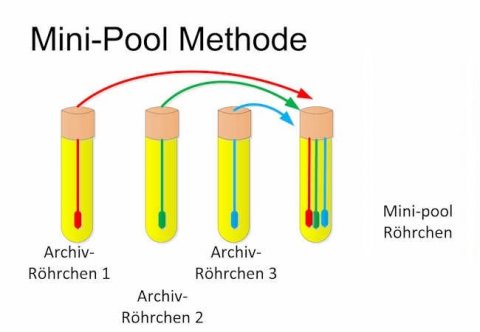
- সাধারণত একজন ব্যক্তির রোগ নির্নয়ের জন্য একটি RTPCRটেস্ট করা হয়। এই প্রক্রিয়ায় ৫০ জন সন্দেহভাজনের জন্য ৫০ টি টেস্ট করতে হবে। আলাদা আলাদা টেস্ট না করে যদি (উদাহরণস্বরূপ) ৫০ জনের স্যাম্পল একসাথে মিশিয়ে একটা RTPCR টেস্ট করা হয় তবে সেটা পুল টেস্টিং।অর্থাৎ পুল টেষ্টিংএর মাধ্যমে একসাথে একটি কিট ব্যবহার একবার RTPCR টেস্ট পরিচালনা করে অনেকজনের টেস্ট করা সম্ভব।
- এই প্রক্রিয়ার সবচেয়ে বড় সুবিধা হচ্ছে একসাথে অনেক জনের (প্রায় ৬৪ জনের একসাথে) টেস্ট করা যায় । এতে টেস্টিং খরচ অনেক কমে এবং দ্রুততম সময়ে অনেকের টেস্ট করা সম্ভব হয়। টেস্ট রেজাল্ট যদি নেগাটিভ হয় তবে সকলকে একসাথে বলে দেওয়া যায় যে তাদের দেহে করোনা ভাইরাস নাই। আর যদি পজিটিভ হয় তবে আবারো ছোট ছোট ভাগে ভাগ করে অল্পসংখ্যক অতিরিক্ত টেস্টের মাধ্যমে নির্নয় করা যাবে কার দেহে করোনা ভাইরাস এর উপস্থিতি আছে আর কার দেহে নাই।
- সবচেয়ে বড় অসুবিধা হচ্ছে যদি সংক্রমনের হার খুব বেশি থাকে তবে এই প্রক্রিয়ায় টেস্ট করে খুব একটা লাভবান হওয়া যায় না। প্রয়োজনের অতিরিক্ত টেস্ট করা লাগতে পারে। যারা এখনো সংক্রমিত হয় নাই তাদের খুঁজে বের করার জন্য পুলটেস্টিং খুব কার্যকর ভূমিকা পালন করতে পারে।
- কোন কোন ক্ষেত্রে পুল টেস্টিং সহায়ক ভূমিকা পালন করতে পারে?
- আগেই বলেছি, প্রবলভাবে অথবা একেবারেই সংক্রমিত হয়নি এমন জনগোষ্ঠী নির্ণয়ের ক্ষেত্রে পুল/ গ্রুপ টেস্টিং শক্তিশালী ভূমিকা পালন করতে পারে। উদারনসরূপ ধরা যাক, একটা হাসপাতালে একজন রোগী অজানা কারণে মৃত্যুবরণ করল। তার উপসর্গ বিবেচনায় রেখে টেস্ট করে দেখা গেল যে রোগীর দেহে করোনা ভাইরাস এর উপস্থিতি ছিল। বিষয়টি খুব উদ্বেগের সাথে পর্যালোচানা করে সিদ্ধান্ত নেওয়া হলো, সকল ডাক্তার, নার্স, টেকনিশিয়ান যারাই রোগীর সংস্পর্সে (প্রত্যক্ষ বা পরোক্ষ) এসছেন সাবাইকে ১৪ দিনের কোয়ারেন্টিনে পাঠিয়ে দিতে হবে। সাথে হাসপাতালটি লক-ডাউন করা হল। এই চিত্রটির সাথে কমবেশি আমরা সকলেই পরিচিত। কারণ বাংলাদেশে বর্তমানে এভাবেই পরিস্থিত মোকাবেলা করা হচ্ছে। এতে সবচেয়ে বড় সমস্যা হচ্ছে, একসাথে অনেক অনেক স্বাস্থ্যসেবাকর্মী সিস্টেমের বাইরে থাকতে হচ্ছে। এমনিতেই আমাদের ডাক্তার, নার্সদের সঙ্কট আছে। তার উপর যদি এভাবে কয়দিন পর পর ১০-২০ জন করে কোয়ারিনটিনে পাঠিয়ে দিতে হয় তবে চিকিৎসাসেবা নিশ্চিত করার জন্য পর্যাপ্ত সেবাদান কর্মী পাওয়া মুশকিল হয়ে পড়বে। এমত অবস্থায় পুল টেষ্টিং আমাদের যেভাবে সাহায্য করতে পারেঃ
- সন্দেহভাজন সকলের স্যাম্পল কালেকশন করে পুল টেস্টিং করে প্রথমেই যাচাই করে নেওয়া যায় তাদের মধ্যে অন্তত একজনও আক্রান্ত কিনা।
- যদি পুল টেস্টিং এর ফলাফল নেগেটিভ হয় তবে সকল স্বাস্থ্যসেবা কর্মী নিরাপদ এবং আগের মত সেবাদান অব্যহত রাখতে পারবেন।
- যদি পুলটেস্টিং এর ফলাফল পজিটিভ হয়, তবে সকলকে কোয়ারেনটিনে রেখে অতিরিক্ত আরো কিছু টেস্টের মাধ্যমে আক্রান্ত ব্যক্তিকে নির্দিষ্ট করে স্বল্প সময়ের মধ্যে বাকিদেরকে সেবাদানে ফিরিয়ে আনা সম্ভব।
- একই উপায়ে অন্যান্য ক্ষেত্রেও গুরুতপূর্ণ ব্যক্তিদের কোয়ারেনটিনে থাকার সময় কমিয়ে আনা সম্ভব যা সেবা কার্যক্রম অব্যহত রাখতে সাহায্য করবে।
- অনুরূপভাবে কোন একটা বিল্ডিংএ যদি একজন আক্রান্ত রোগী পাওয়া তবে বাকিদের স্যাম্পল নিয়ে পুল টেস্টিং করে নির্ণয় করা যাবে অন্যরা আক্রান্ত কি না।
- বিদেশ থেকে আগত ব্যক্তিদের ক্ষেত্রেও পুলটেষ্টিং মাধ্যমে কর্যকরী কোয়ারেনটিন নিশ্চিত করা সম্ভব।
- পুল টেস্টিং ের মাধ্যমে আক্রান্ত এলাকায় অনাক্রান্ত অংশ বা আরিয়া সহজেই আলাদা করা সম্ভব।
- আগেই বলেছি, প্রবলভাবে অথবা একেবারেই সংক্রমিত হয়নি এমন জনগোষ্ঠী নির্ণয়ের ক্ষেত্রে পুল/ গ্রুপ টেস্টিং শক্তিশালী ভূমিকা পালন করতে পারে। উদারনসরূপ ধরা যাক, একটা হাসপাতালে একজন রোগী অজানা কারণে মৃত্যুবরণ করল। তার উপসর্গ বিবেচনায় রেখে টেস্ট করে দেখা গেল যে রোগীর দেহে করোনা ভাইরাস এর উপস্থিতি ছিল। বিষয়টি খুব উদ্বেগের সাথে পর্যালোচানা করে সিদ্ধান্ত নেওয়া হলো, সকল ডাক্তার, নার্স, টেকনিশিয়ান যারাই রোগীর সংস্পর্সে (প্রত্যক্ষ বা পরোক্ষ) এসছেন সাবাইকে ১৪ দিনের কোয়ারেন্টিনে পাঠিয়ে দিতে হবে। সাথে হাসপাতালটি লক-ডাউন করা হল। এই চিত্রটির সাথে কমবেশি আমরা সকলেই পরিচিত। কারণ বাংলাদেশে বর্তমানে এভাবেই পরিস্থিত মোকাবেলা করা হচ্ছে। এতে সবচেয়ে বড় সমস্যা হচ্ছে, একসাথে অনেক অনেক স্বাস্থ্যসেবাকর্মী সিস্টেমের বাইরে থাকতে হচ্ছে। এমনিতেই আমাদের ডাক্তার, নার্সদের সঙ্কট আছে। তার উপর যদি এভাবে কয়দিন পর পর ১০-২০ জন করে কোয়ারিনটিনে পাঠিয়ে দিতে হয় তবে চিকিৎসাসেবা নিশ্চিত করার জন্য পর্যাপ্ত সেবাদান কর্মী পাওয়া মুশকিল হয়ে পড়বে। এমত অবস্থায় পুল টেষ্টিং আমাদের যেভাবে সাহায্য করতে পারেঃ
জার্মানি, ইজরায়েল ও ইন্ডিয়া পুলটেস্টিং প্রক্রিয়ার মাধ্যমে তাদের টেস্টিং ক্যাপাসিটি বাড়ানোর কার্যক্রম শুরু করেছে। আমাদের দেশের পরিপ্রেক্ষিতে পুল টেষ্টিং দারুণ সুফল বয়ে আনতে পারে। যেহেতু আমাদের কিট স্বল্পতা আছে, পুল টেস্টিং আমাদের জন্য আদর্শ উপায় হতে পারে অধিক টেস্টিং নিশ্চিত করার ক্ষেত্রে।
সামাজিক দূরত্ব বজায় রাখুন। যথা সম্ভব ঘরে থাকুন। নিজেকে সুস্থ রাখুন। অন্যকেও নিরাপদ এ রাখুন।
নোটঃ
আমি মলিকূলার বায়োলজিষ্ট নই।RTPCR টেস্ট আমি কখনো করিনি। রেফারেন্সে দেওয়া তথ্যসূত্র পড়ে এবং নিজের কিছু অর্জিত জ্ঞান একীভূত করে নিজের মতামত প্রকাশ করেছি। এই প্রক্রিয়ায় আরো অন্যান্য জটিলতা থাকতে পারে যা হয়ত এই রেফারেন্সগুলতে প্রকাশিত হয়নি এবং আমি এখনো জানি না। এবং ওই সকল জটিলতার কারণে হয়টা বাংলাদেশে এই প্রক্রিয়ায় টেস্টিং সম্ভব নাও হতে পারে। আইইডিসিআর নিশ্চয়ই বিষটি সম্পর্কে সচেতন আছেন। বিস্তারিত তথ্যের জন্য এবং সত্য যাচাই করার জন্য সকলকে নিমোক্ত রেফারেন্স গুলা পড়ে দেখার অনুরোধ রইল।
রেফারেন্সঃ
১। pool-testing-of-sars-cov-02-samples-increases-worldwide-test-capacities-many-times-over
৪। icmr-suggests-pool-testing-to-increase-number-of-coronavirus-tests-cut-costs-5143921.html
